OLID-BR#
O Offensive Language Identification Dataset for Brazilian Portuguese (OLID-BR) é um conjunto de dados com anotações multiplas tarefas para a detecção de linguagem ofensiva.
A versão atual (v1.0) contém 7.943 (extensível para 13,538) comentários de diferentes fontes, incluindo mídias sociais (YouTube e Twitter) e conjuntos de dados relacionados.
OLID-BR contém uma coleção de comentários em Português do Brasil anotados que abrangem os seguintes níveis:
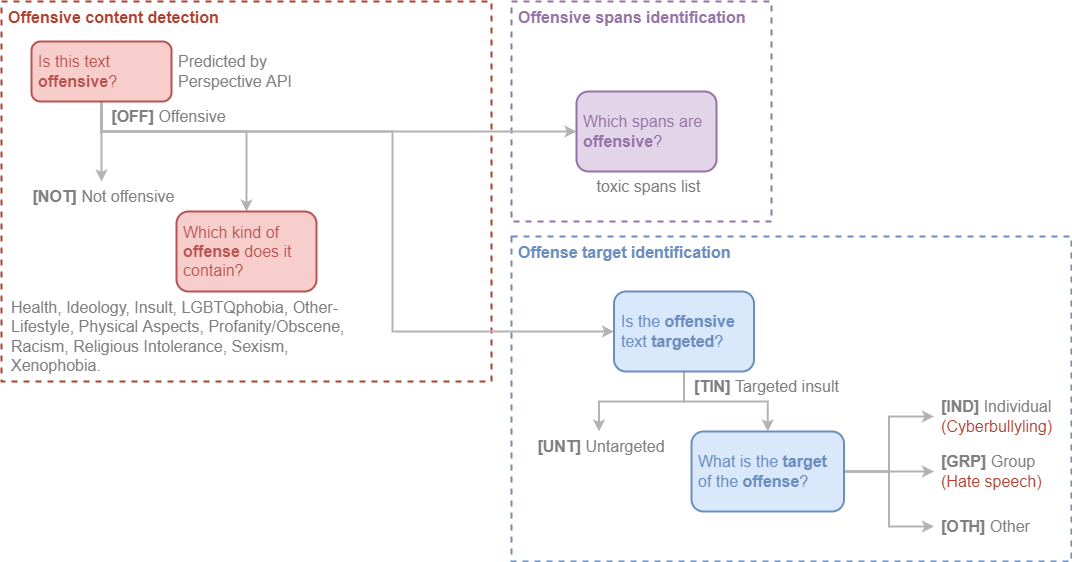
Categorização#
Offensive content detection#
Este nível é usado para detectar conteúdo ofensivo em uma frase.
Este texto é ofensivo?#
Nós utilizamos a Perspective API para detectar se um comentário é ofensivo ou não. Adicionalmente, nossos anotadores reclassificaram comentários identificados como ofensivos incorretamente.
OFF: O comentário é ofensivo.NOT: O comentário não é ofensivo.
Qual tipo de ofensa o texto contém?#
Os rótulos abaixo foram anotados pelos nossos anotadores.
Health, Ideology, Insult, LGBTQphobia, Other-Lifestyle, Physical Aspects, Profanity/Obscene, Racism, Religious Intolerance, Sexism e Xenophobia.
Veja Glossary para maiores informações.
Offense target identification#
Este nível é usado para detectar se um comentário ofensivo é direcionado a um indivíduo, grupo de pessoas ou outros.
Este comentário ofensivo é direcionado a alguém?#
TIN: O comentário é direcionado a um indivíduo, grupo de pessoas ou outros.UNT: O comentário não é direcionado.
Qual o alvo do comentário ofensivo?#
IND: O comentário é direcionado a um indivíduo. Também conhecido como Cyberbullying.GRP: O comentário é direcionado a um grupo de pessoas. Também conhecido como Hate Speech.OTH: O comentário é direcionado a outras categorias, como uma organização, um evento, etc.
Offensive spans identification#
Os toxic spans fornecem uma lista com os caracteres de um determinado comentário que são considerados ofensivos.
Por exemplo, vamos considerar o comentário:
"USER
CanalhaURL"
Os toxic spans são:
1 | |
Estrutura do conjunto de dados#
Instâncias de dados#
Cada instância é um comentário de mídia social com um ID e anotações correspondentes para todas as tarefas descritas abaixo.
Campos de dados#
A configuração simplificada inclui:
id(string): Identificador único da instância.text(string): O texto da instância.is_offensive(string): Se o texto é ofensivo (OFF) ou não (NOT).is_targeted(string): Se o texto é direcionado (TIN) ou não direcionado (UNT).targeted_type(string): Tipo de destino (individualIND, grupoGRPou outroOTH). Disponível apenas seis_targetedforTrue.toxic_spans(string): Lista de spans tóxicos.saúde(booleano): Se o texto contém discurso de ódio com base em condições de saúde, como deficiência, doença, etc.ideologia(boolean): Indica se o texto contém discurso de ódio baseado nas ideias ou crenças de uma pessoa.insult(boolean): se o texto contém conteúdo insultuoso, inflamatório ou provocativo.lgbtqphobia(booleano): se o texto contém conteúdo nocivo relacionado à identidade de gênero ou orientação sexual.other_lifestyle(boolean): Se o texto contém discurso de ódio relacionado a hábitos de vida (por exemplo, veganismo, vegetarianismo, etc.).physical_aspects(boolean): Se o texto contém discurso de ódio relacionado à aparência física.profanity_obscene(boolean): Se o texto contém palavrões ou conteúdo obsceno.racism(boolean): Se o texto contém pensamentos preconceituosos ou ações discriminatórias baseadas em diferenças de raça/etnia.religious_intolerance(boolean): Se o texto contém intolerância religiosa.sexism(booleano): se o texto contém conteúdo discriminatório com base em diferenças de sexo/gênero (por exemplo, sexismo, misoginia, etc.).xenophobia(boolean): Se o texto contém discurso de ódio contra estrangeiros.
Consulte a página Get Started para obter mais informações.
Considerações para usar os dados#
Impacto social do conjunto de dados#
A detecção de toxicidade é um valioso problema para ser estudado que pode garantir um ambiente online mais seguro para todos.
No entanto, os algoritmos de detecção de toxicidade têm se concentrado no inglês e não consideram as especificidades de outros idiomas.
Isso é um problema porque a toxicidade de um comentário pode ser diferente em diferentes idiomas.
Além disso, os algoritmos de detecção de toxicidade focam na classificação binária de um comentário como tóxico ou não tóxico.
Portanto, acreditamos que o conjunto de dados OLID-BR pode ajudar a melhorar o desempenho dos algoritmos de detecção de toxicidade em português brasileiro.
Discussão de preconceitos#
Estamos cientes de que o conjunto de dados contém vieses e não é representativo da diversidade global.
Estamos cientes de que a linguagem usada no conjunto de dados pode não representar a linguagem usada em diferentes contextos.
Possíveis vieses nos dados incluem: Preconceitos inerentes nas mídias sociais e vieses da base de usuários, as listas de palavras ofensivas/vulgares usadas para filtragem de dados e vieses inerentes ou inconscientes na avaliação de rótulos de identidade ofensivos.
Tudo isso provavelmente afeta a rotulagem, a precisão e a recuperação de um modelo treinado.
Citação#
Pending
Referências#
O conjunto de dados OLID-BR é baseado no conjunto de dados OLID proposto por Zampieri et al. (2019)1 e outros trabalhos relacionados.
-
Zampieri et al. "Predicting the type and target of offensive posts in social media." NAACL 2019. ↩
-
João A. Leite, Diego F. Silva, Kalina Bontcheva, Carolina Scarton (2020): Toxic Language Detection in Social Media for Brazilian Portuguese: New Dataset and Multilingual Analysis. Published at AACL-IJCNLP 2020. ↩
-
S. Malmasi, "Offensive Language Identification Dataset - OLID", Scholar.harvard.edu, 2021. [Online]. Available: https://scholar.harvard.edu/malmasi/olid. [Accessed: 28- Aug- 2021]. ↩
-
Weng, L. (2021, March 21). Reducing toxicity in language models. Lil'Log. https://lilianweng.github.io/lil-log/2021/03/21/reducing-toxicity-in-language-models.html. ↩