Data Pipeline#
In this section, we describe the data pipeline used to generate the dataset.
Data Source#
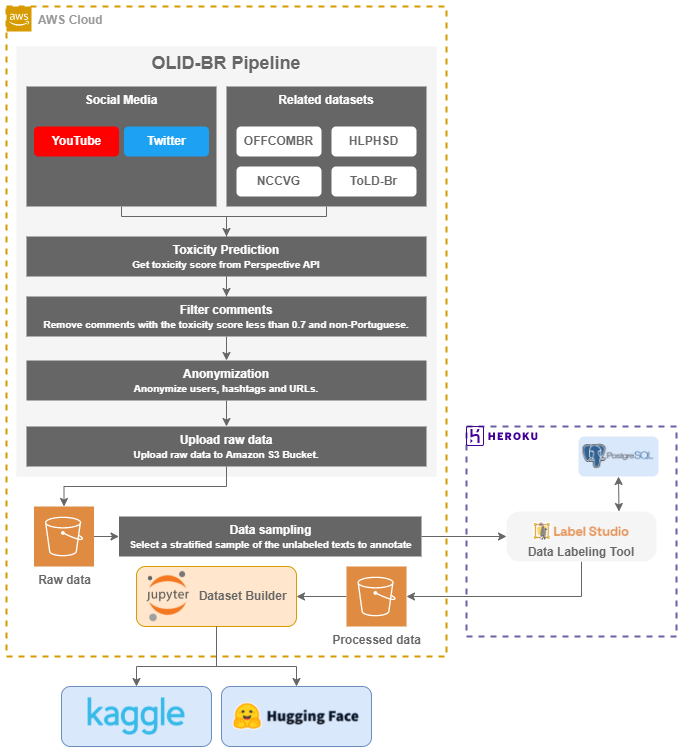
We collected comments from different sources, such as Twitter, YouTube, and related datasets.
For each social media (Twitter and YouTube), we defined a set of public profiles that we considered relevant to the topic.
Additionally, we used Brazilian texts from other datasets, such as:
- rogersdepelle/OffComBR: Here we provide a data set of web comments which have been annotated for hate speech.
- paulafortuna/Portuguese-Hate-Speech-Dataset: A Hierarchically-Labeled Portuguese Hate Speech Dataset
- LaCAfe/Dataset-Hatespeech: Hate Speech Detection Dataset
- JAugusto97/ToLD-Br: Toxic Language Detection in Social Media for Brazilian Portuguese: New Dataset and Multilingual Analysis
Architecture#
The following diagram shows the architecture of the data pipeline.
Filtering#
We want to filter out comments that are not relevant to the scope of the dataset.
- Comments must be in Portuguese.
- Comments that have one or more related keywords.
Privacy#
We will apply some privacy policies to the comments collected from each source directly in the ingestion pipeline.
- User mentions were replaced with the word "@USER".
- URLs were replaced with the word "URL".
Last update:
March 1, 2023